Linux 提供的模块机制能动态扩充 linux 功能而无需重新编译内核,已经广泛应用在 linux 内核的许多功能的实现中。

不知你看到这段话时是否和我一样脱口而出 MD! ZZ! ,毕竟上一个通过重新编译内核扩充 Linux 功能的实验耗时之久令人印象深刻。哪成想今天区区几分钟就和曾经编译几小时达到一样的效果。不禁感先人之伟大,觉自己之智障。废话少说,我们直奔主题!
实验要求
(1) 设计一个模块,要求列出系统中所有内核线程的程序名、PID、进程状态、进程优先级及父进程PID。
(2) 设计一个带参数的模块,其参数为某个进程的 PID 号,该模块的功能是列出该进程的家族信息,包括父进程、兄弟进程和子进程的程序名、PID 号、进程状态。
(3) 请根据自身情况,进一步阅读分析程序中用到的相关内核函数的源码实现。
准备
1 | mkdir os_2 # 新建文件夹 |
模块一(无参)
编辑模块
1 | cd all_task |
1 | // /home/user/os_2/all_task/all_task.c |
编辑 Makefile
1 | vim Makefile |
1 | obj-m := all_task.o |
[*] Caution! make 前是 TAB 而非多个 ,错误缩进会高亮报错且导致编译错误,比如像下面这样
编译模块
1 | make # 编译模块 |
加载模块
1 | insmod all_task.ko # 尝试加载模块,发现权限不够 |
查看结果
1 | dmesg # 在日志文件中查看结果 |
检验结果
1 | ps aux # ps aux 列出所有进程/线程,COMMAND 带有 [ ] 的为内核线程 |
1 | # 表头具体含义 |
卸载模块
1 | rmmod all_task.ko # 卸载模块 |
实验详解
[*] Caution! 下面所有源码的引用均以 v4.18.12 为例,均以 linux 内核所在的目录为根目录
Process & Thread
进程(英语:process),是计算机中已运行程序的实体。进程为曾经是分时系统的基本运作单位。
是具有一定独立功能的程序关于某个数据集合的一次运算过程,是系统进行资源分配和调度的独立单位。
进程的两个基本元素:一个或一组可执行的程序、与程序有关的数据集。
线程(英语:thread)是操作系统能够进行运算调度的最小单位。它被包含在进程之中,是进程中的实际运作单位。一条线程指的是进程中一个单一顺序的控制流,一个进程中可以并发多个线程,每条线程并行执行不同的任务。
在Unix System V及SunOS中也被称为轻量进程(lightweight processes),但轻量进程更多指内核线程(kernel thread),而把用户线程(user thread)称为线程。
task_struct
task_struct被称为进程描述符(process descriptor),是Linux内核的一种数据结构。它会被装载到RAM中并且包含着进程的信息。每个进程都把它的信息放在 task_struct 这个数据结构体。
1 | // ./include/linux/sched.h |
mm_struct
咳咳!敲黑板!
task_struct被称为'进程描述符'(process descriptor),因为它记录了这个进程所有的context。其中有一个数据结构mm_struct,被称为'内存描述符'(memory descriptor),抽象地描述了Linux视角下管理进程地址空间的所有信息。
每个进程都有自己独立的mm_struct,使得每个进程都有一个抽象的平坦的独立的地址空间,各个进程都在各自的地址空间中相同的地址内存存放不同的数据而且互不干扰。如果进程之间共享相同的地址空间,则被称为线程。
1 | // ./include/linux/mm_types.h |
Process & Kernel Thread
每个进程描述符都包含:
mm和active__mm,其中mm成员指向进程拥有的内存描述符,而active_mm则指向当前正在执行的内存描述符。
对于普通进程来说,二者是一样的;但是对于kernel线程没有内存描述符,mm为空,active_mm指向前一个执行进程的mm。
list_head
1 | // ./drivers/gpu/drm/nouveau/include/nvif/list.h |
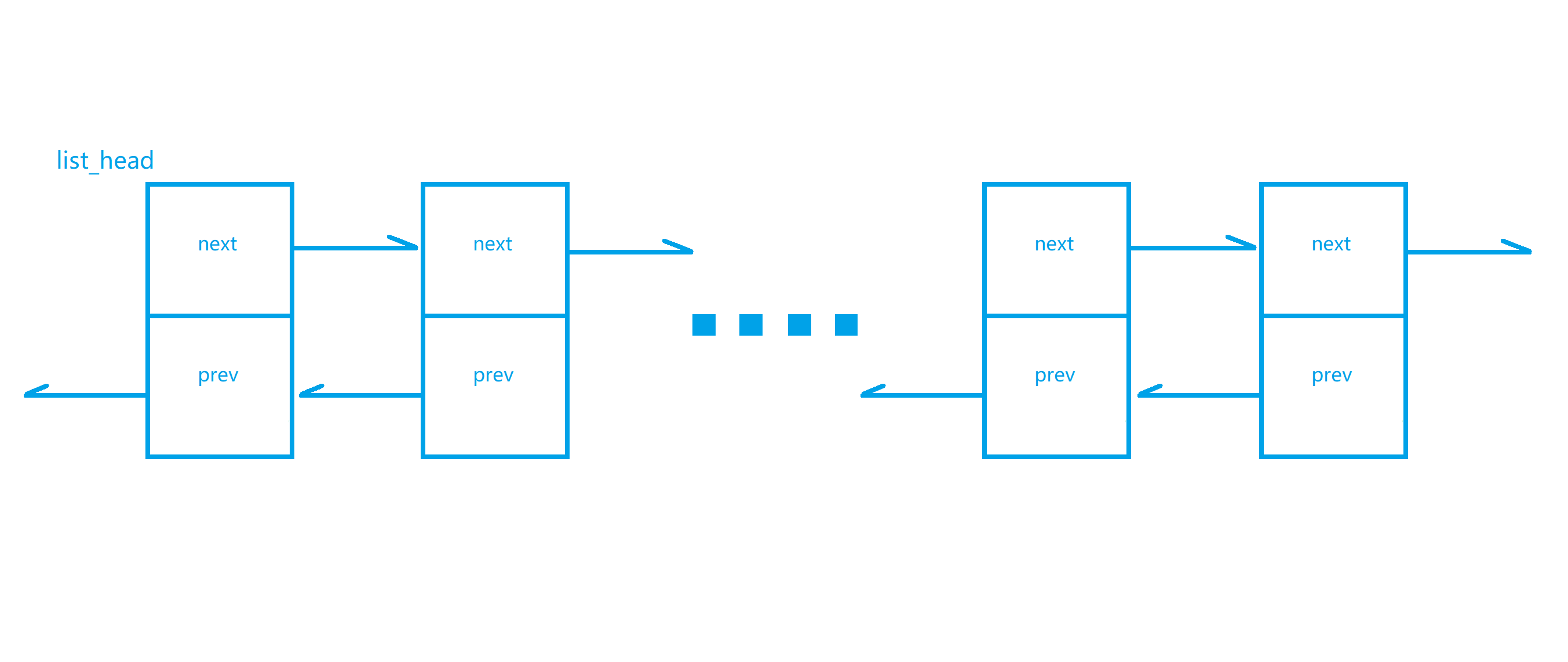
如图所示(随手画的,请别挑剔),结构体
list_head包含两个指针成员:next,prev。这两个指针成员都是list_head类型,以此构成链表。实际应用中,list_head结构体往往实例化为其他结构体的成员,可以参考task_struct中的children,sibling。
for_each_process()
此宏的功能是依次访问链表的每个进程
1 | // /include/linux/sched/signal.h |
模块二(含参)
编辑模块
1 | cd .. # 返回上一级目录,即 os_2 根目录 |
1 | // /home/user/os_2/family_task/family_task.c |
编辑 Makefile
1 | vim Makefile |
1 | obj-m := family_task.o |
[*] Caution! 再次提醒,make 前是 TAB 而非多个 ,错误缩进会高亮报错且导致编译错误,比如像下面这样
编译模块
1 | make # 编译模块 |
加载模块
1 | su root # 启用 root 权限 |
查看结果
1 | dmesg |
检验结果
1 | pstree -p 0 # pstree -p <pid> 查看某进程的进程家族树 |
卸载模块
1 | rmmod family_task.ko # 卸载模块 |
实验详解
灵魂画师再次放上神图,此图一出,代码即一目了然,再多解释都是枉然!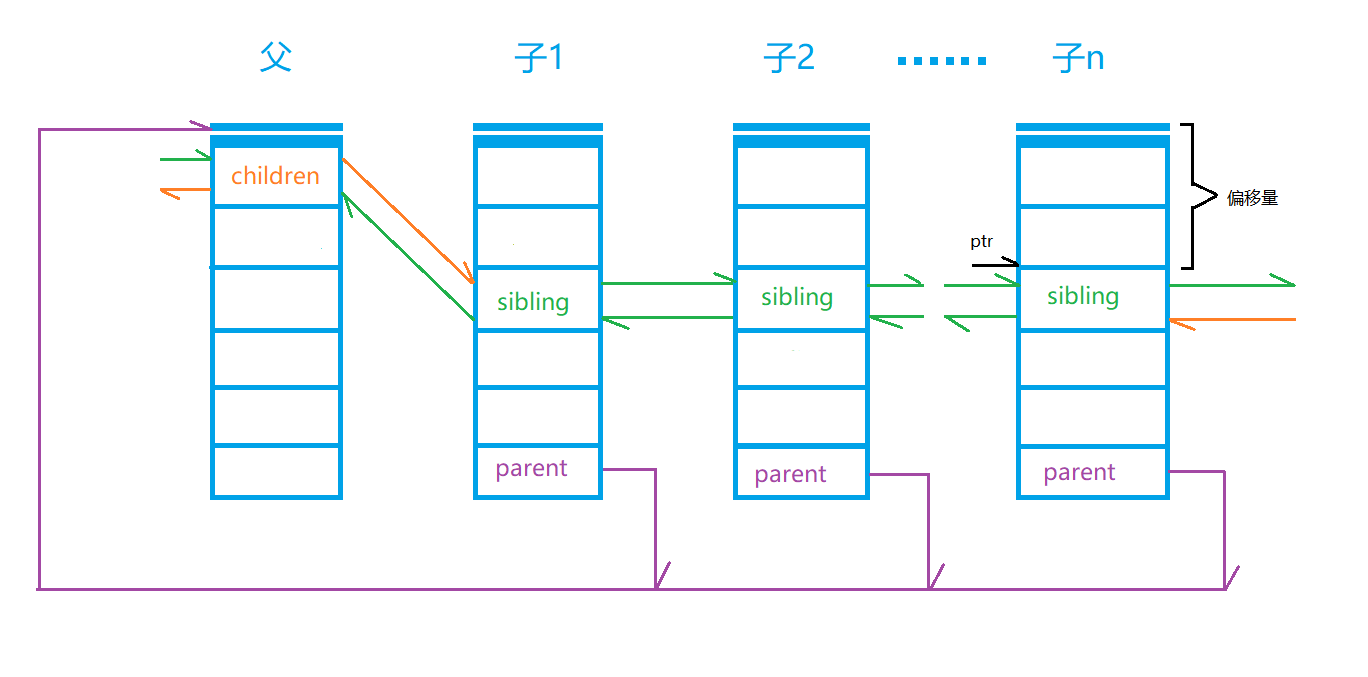
当然,我还是会主要部分尽量事无巨细地解释的。
find his children
(1)已知甲进程,欲获得 甲进程所有子进程的信息,即此时甲进程为图中的 父 ,寻其 子 的方式一目了然。
(2)欲获得乙进程所有信息,需要获得该数据结构首地址。
(3)已知某数据结构指向某数据结构成员的指针 ptr ,和该成员的偏移量offset ,可计算该数据结构首地址,即 ptr - offset
find his sibling
(1)已知甲进程,欲获得 甲进程所有兄弟进程的信息,即此时甲进程为图中的 子X ,寻其兄弟及获取兄弟信息的方式类比上文。

恭喜你,又做完一个实验!下次再见!
Remarks
本文编写时主要的参考的资料如下: